절차적 프로그래밍
들어가며
혹시 절차적 프로그래밍을 '주어진 명령을 순서대로 수행하는 프로그래밍 패러다임' 이라고 생각하고 있지는 않은가?
객체지향 프로그래밍은 절차적 프로그래밍과는 다른 패러다임이라고 생각하지는 않는가?
두 경우는 절차적 프로그래밍과 관련된 대표적인 오해이다. 이 글을 읽고나면 위 오해를 깔끔하게 해결할 수 있을 것이다.
절차적 프로그래밍의 탄생 과정
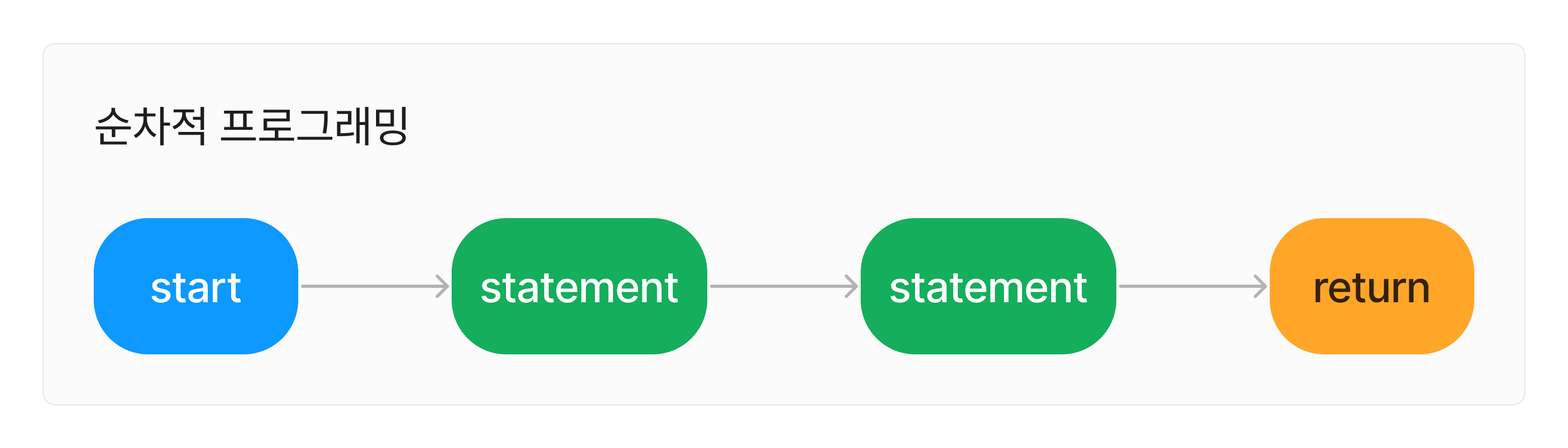
가장 기본적인 프로그래밍 패러다임이 있었을 것이다. 이를 순차적 프로그래밍이라고 부르겠다.
순차적 프로그래밍에서는 하나의 statement가 실행되고 또 그다음 statement가 실행되고... 이를 반복한다.
근본있는 방식이지만 프로그래머들이 코딩을 하다보니 두 가지 단점을 발견했다.
-
프로그램의 크기가 커질수록 어떤 코드가 무슨 일을 하는지 구분하기 어렵다.
-
반복적으로 쓰이는 코드 덩어리가 생긴다.
이를 해결하기 위해 과거의 프로그래머들은 프로시저라는 개념을 탄생시켰다.
프로시저를 잘 활용하여 코딩하는 방법론이 바로 절차적 프로그래밍(procedural programming)이다.
프로시저를 바구니라고 생각해보자. 코드를 프로시저로 묶는다는건 흩여져있는 물건들을 잘 정리해서 바구니안에 담은것이다.
바구니에 잘 담아서 바구니마다 이름표를 붙여두면 어떤 물건이 어딨는지 찾고 싶을 때 찾기 쉽다.
현실 세계에서는 바구니를 복사할 수 없지만, 컴퓨터는 바구니를 복사할 수 있다. 기능을 구현하기 위해 새로 개발하는 것 보다, 이미 만들어진 프로시저를 가져다 쓰면 무척 편할 것이다.
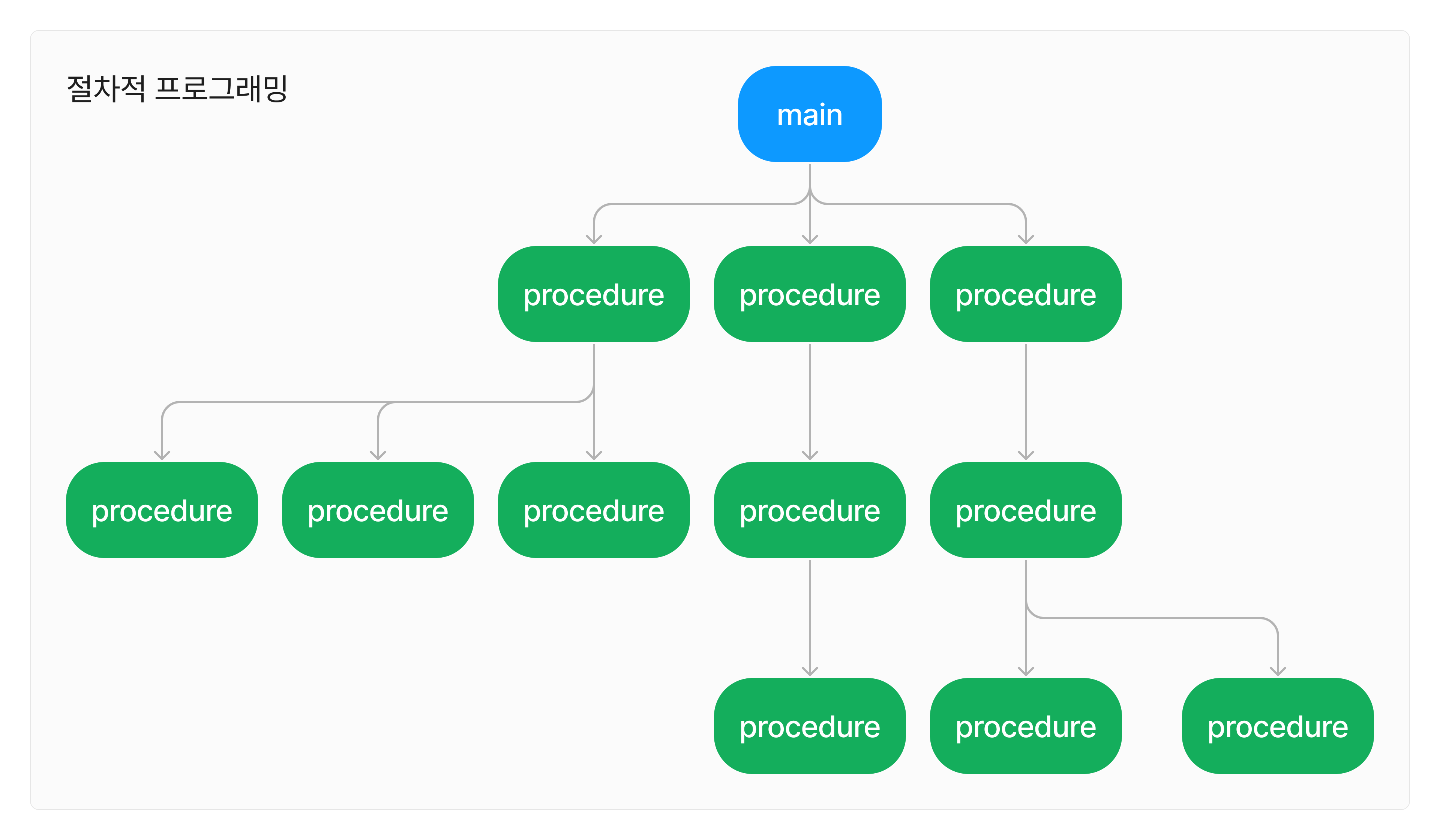
절차적 프로그래밍이 등장하면서 거대한 프로그램을 작은 프로그램 여러 개로 분해할 수 있게 되었다.
또한 기존에 선형적으로 짜던 프로그램을 그래프처럼 구조화 할 수 있게 되었다.
함수
위 설명을 읽고 나면 함수의 설명과 매우 흡사해 보인다. 함수가 프로시저이기 때문이다. 현대에는 프로시저란 말을 거의 쓰지 않으며 그 의미를 함수라는 이름으로 대신한다.
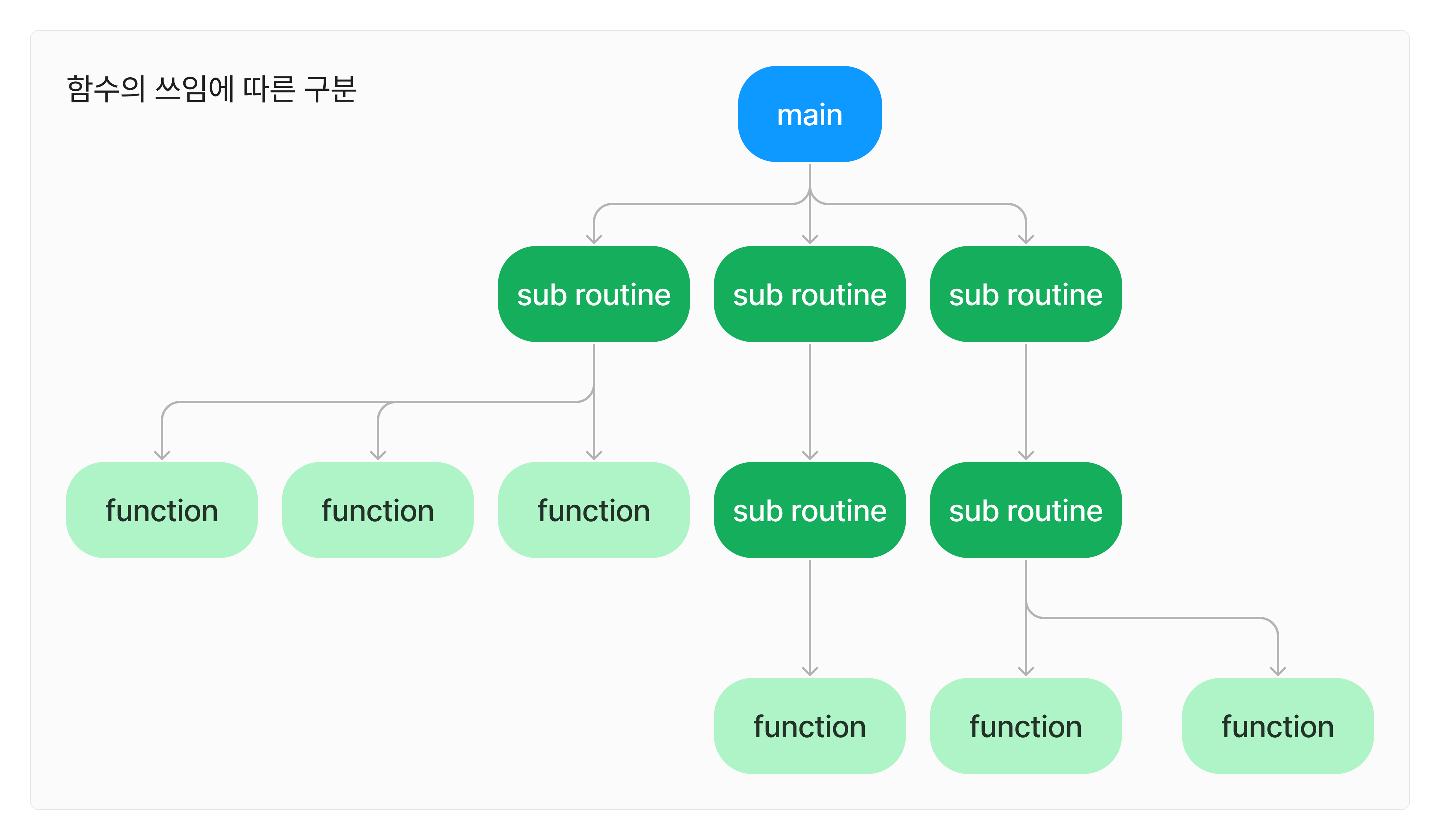
우리는 모든 프로시저를 그냥 함수라고 부르고 있다. 내 경험상 함수는 역할에 따라 두 가지로 구분할 수 있었다.
다른 프로시저를 호출하는 역할을 가지는 프로시저, 계산 혹은 간단한 로직을 수행하는 프로시저로 나눌 수 있다. 전자를 서브루틴, 후자를 함수라고 하겠다.
아래 간단한 예시를 보자.
// shop.js
function printReciept() {
return `${calculatePrice(10000,4)원 입니다. ${getStoreName()}}`
}
function calculatePrice(menuPrice, numberOfCustomer) {
return menuPrice * numberOfCustomer;
}
function getStoreName() {
return '프라이빗노트';
}두 함수가 하는 일은 사뭇 다르다.
printMenu 함수는 console.log를 사용해서 콘솔에 문자열을 출력하고 있다. 리턴값도 없다.
calculatePrice 함수는 menuPrice와 numberOfCustomer라는 인자를 받아서 내야할 총 금액을 계산하여 리턴한다.
getStoreName 함수는 가게의 이름을 리턴한다.
printMenu 함수는 서브루틴일 것이고 calculatePrice와 getStoreName은 함수라고 할 수 있겠다.
이를 명확하게 구별하여 코딩하면 읽기 쉽다.
서브루틴은 함수를 어떤 순서로 호출할지 결정한다. 그 외 다른 로직은 최소화해야 한다. 덕분에 어떤 흐름으로 프로그램이 진행될 지 한눈에 파악할 수 있다.
더 세부적인 로직을 알고 싶으면 함수를 읽는다. 함수는 가장 구체적인 내용을 담고 있어서, 버그를 수정해야 할 때 건드리게 된다.
절차적 프로그래밍의 단점, 객체지향 프로그래밍의 도래
절차적 프로그래밍은 상당히 강력한 패러다임이였으며 오래 사용되어 왔다.
그러나 소프트웨어가 점점 커지고 복잡해지면서 절차적 프로그래밍의 단점이 드러나게 되었다. 바로 상태를 관리하기 쉽지 않다는 점이다.
상태란 변하는 값이다. 상태는 여러 함수에 의해 계속 바뀐다.
여러 함수에서 무분별하게 상태를 바꾸다보면 상태가 어떻게 바뀌고 있는지 추적하기 어려워진다.
어떤 상태를 참조하는 새로운 함수를 추가할 때마다 이 상태가 어떻게 바뀌고 있는지 잘 살펴보지 않으면 버그를 터트리게 되기 쉬웠다.
이를 해결하기 위해 클래스를 만들었다. 클래스는 상태를 소유한다. private인 상태는 그 클래스가 가진 함수인 메소드에서만 접근이 가능하다. 이를 캡슐화라 부른다.
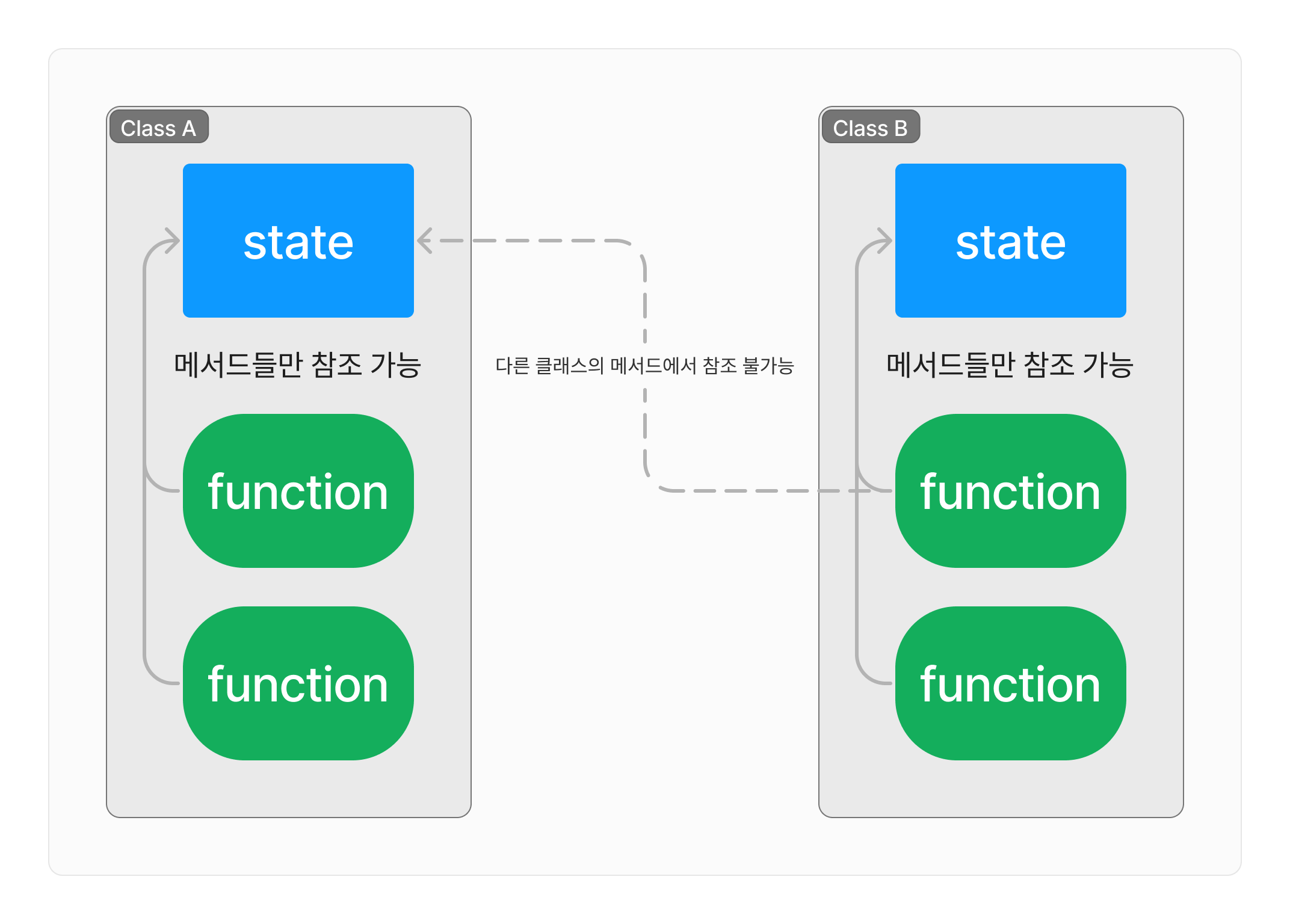
객체지향 프로그래밍의 근본은 절차적 프로그래밍이며 클래스는 상태와 메서드를 캡슐화하는 구조라고 할 수 있다.
마치며
절차적 프로그래밍은 가장 기본적인 프로그래밍 기법이다. 그 뜻을 이해하고 코드를 짜면 훨씬 이해하기 쉬운 코드가 될 것이다.
만약 한 함수의 길이가 너무 길다면, 그 함수가 하는 역할이 너무 많은게 아닌지 고민해보자. 코드를 잘게 쪼갤수록 프로그램의 흐름을 파악하기 쉬워지고 세부적인 로직을 이해하기 쉬워질 것이다.